
読売新聞寄稿連載「ドキ★ワク先端科学」から~
第49回:情報科学研究科 知能コミュニケーション研究室 中村哲教授 〔2017年6月21日〕
「音声通訳 外国人と会話」

異なる言葉を話す外国人と自由に話ができたら、というのは人類の長年の夢。これをコンピューターで実現するのが音声自動通訳の技術です。この技術による処理の構成を図に示します。
まず、我々が話した音声を、コンピューターが単語の連なりに変換(音声認識)します。相手の言語に自動翻訳(機械翻訳)した後、翻訳された言語を、コンピューターが音声化(音声合成)することで、会話を可能にします。
この研究は1986年、世界に先駆けた日本の国家プロジェクトとして、けいはんな学研都市の国際電気通信基礎技術研究所で始まりました。私も開始時から携わっています。
当初は1000単語ほどの音声認識や、ごく限られた文を訳すのが精いっぱいでした。しかし30年を経て、旅行会話程度の、短くて簡単な文法の発話なら音声自動通訳が可能になりました。
今では、機械学習や人工知能、深層ニューラルネットワークといった最新の情報技術を駆使しています。例えば機械翻訳では、コンピューターが二つの言語で同じ意味を持つ文のペアを100万文以上収集し、対応する単語を見つけ出し、単語の組み合わせや出現順序の入れ替えを自動的に学習します。
2020年の東京五輪・パラリンピックに向けて、総務省や情報通信研究機構は訪日外国人への音声通訳サービスを実現しようと、研究を加速させています。
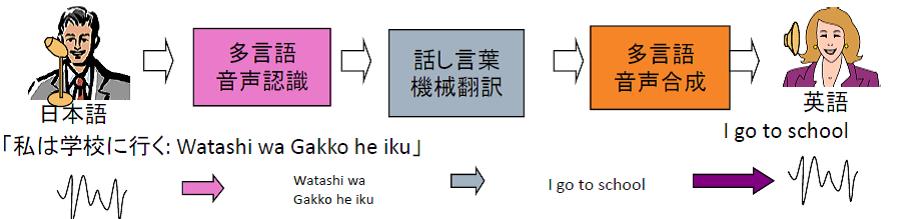
ただ、図のような現在の方式では、相手が話し終わるまで翻訳処理を始められないのが弱点。話が途切れない講演などでは、人間の同時通訳者のように、内容を理解し、次の展開を予測しながら、話の途中で適切な訳出をしていく必要があるのです。
日本語の話し言葉は主語がよく省略され、述語や否定の言葉が文末に登場するといった性質があり、英語などに訳す場合、通訳者は頭をフル回転させて訳していきます。我々の研究室では、通訳者が行う高度な処理をコンピューターで実現すべく、日々研究に取り組んでいるのです。


