
~広報誌「せんたん」から~
[2014年5月号]
情報科学研究科 自然言語処理学研究室 松本裕治教授、ケビン・デュー助教

言語解析の定番
グローバル化し共通の理解を深める中で、言葉によるコミュニケーションはますます重 要になっている。また、ビッグデータの時代 にインターネットのウェブなどにある膨大な 多言語の文書の中から、求める情報を自動的に検索できるシステムが求められている。こうした言語(自然言語)の処理の課題は、計算能力が高いコンピューターの支援なくして は到底、解決できない。
このような状況の中で、松本研究室では「人 間の知能の本質である自然言語の計算機によ る解析と理解」を中心のテーマに据え、言語 の構造を解明して法則を見つけだし、定式化 する研究を重ねている。応用面では、機械翻 訳や文献情報の自動抽出など幅広いテーマを 掲げている。
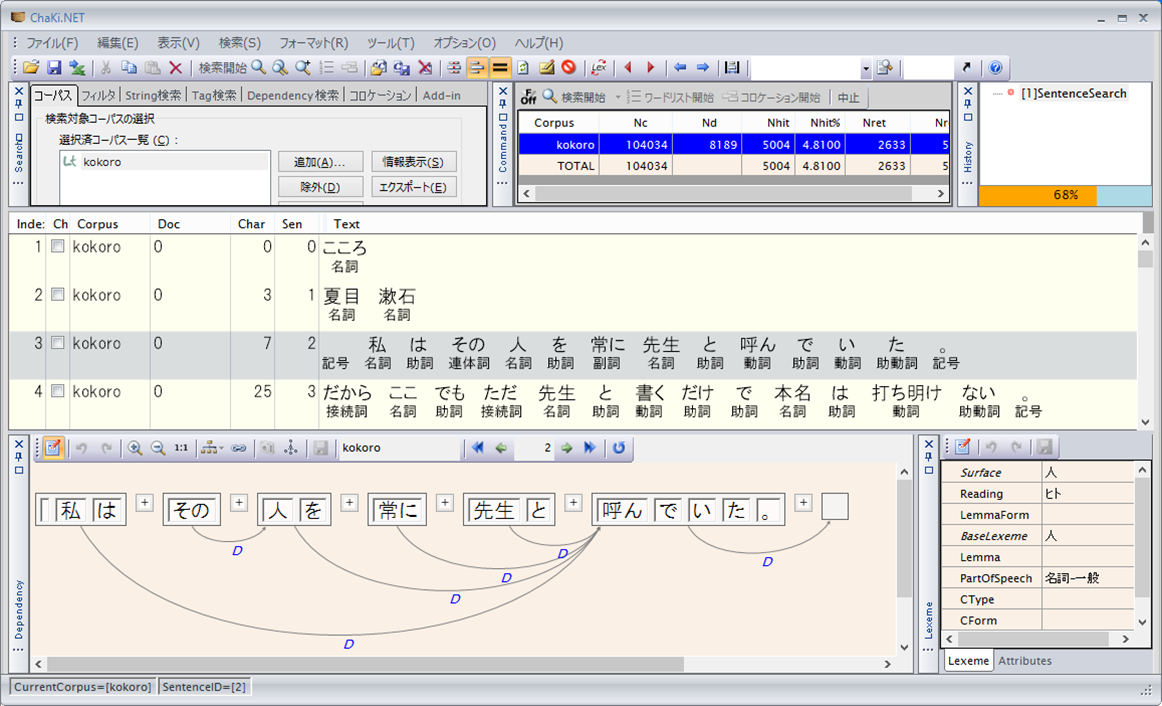
松本研究室と言えば、多様な言語解析シス テムの開発、公開で知られる。日本語の意味を持つ最小単位である「形態素」を解析する システム「茶筌(ちゃせん)」は日本語の単語 分かち書きの基盤ツールなどに使われ、全国 の研究機関で定番の共有ツールになっている。
「言葉の理解という究極の目的のために、文 の構造の解析をしたり、それが表す意味を解析したりしています」と松本教授。言語は、 単語が組み合わさって動詞句、名詞句という 固まりをつくり、それが結び合って文になり、 新たな意味をつくる。「その意味に至るプロセ スを解明するツールをつくり、公開することがメインです」と説明する。
進化する機械翻訳
応用面の研究課題の中で機械翻訳について は「母国語ではない言語で書くときの文法の誤りなどを自動的に訂正するようなところに まで結びつけていきたい」と話す。
松本研究室の機械翻訳の辞書は、日本語(14 万語)と英語(7 万語)、中国語(16 万語)が入っている。ところが、たとえば英語の「プロテイン」は日本語でカタカナ表記すると、 タンパク質の意味以外に筋肉増強のサプリメントの意味もあって「曖昧(あいまい)」だ。この違いは人間なら簡単に見分けるが、機械 には難しい。人間の手で、医学など分野別に 意味をラベルで表示して訳し分けても、言語 には10万個― 20万個の単語があり、組み合わせは掛け算で億単位になるのだから、この作業も大変だ。
そこで、大規模な多言語の文書データについて、対訳がある一部の単語を手掛かりに自動的に分野別に分類する統計的機械学習とい う手法を使った。すると、自動的に蓄積され たデータをもとに、特定の分野に属する可能性の割合が表示されるので、機械でも「曖昧さ」をある程度解消できるのだ。
「この方法だと新たなデータが蓄積された時点で、再度、計算し直して翻訳の精度を高めることができる。ただ、最初に人間が教えないと解析できない文書もあり、うまくすみ分けさせる方法を考えています」という。
さらに、複雑な構造の英文の機械翻訳の精 度を高めるため、大規模な英文の蓄積データ を網羅的に解析するマイニングという手法を 使って、英文の繰り返し構造を数百パターンに分類し文脈を明示する研究も進めている。
また、ツイッターなどソーシャルメディアのビッグデータから、特定の物事についての評価の情報を検索するのに使えるような言語 処理の基盤技術の研究も行っている。
松本教授は「人間の知識が、言語を媒介と してどのように整理されているか知りたい」という思いから、コンピューターによる言語 解析の研究に入った。1980 年代に、人工知 能をめざした経済産業省(当時通商産業省)の第五世代コンピュータープロジェクトに参加し、自然言語処理のベースにある「並列論 理型言語による構文解析」というテーマに取 り組んだ。その後、京都大学、本学へと移ったが、一貫して言語処理をベースに研究を発 展させている。
このように研究一筋だが、趣味は合気道で初段の腕前。「いかに力を使わず相手を倒すか、 合理的です。これも一つのコミュニケーションですね」。
研究室は多彩
「言語処理の研究は多様な分野の知識が必要です。その点、本学は、さまざまな分野を学んだ研究者、学生が所属できる環境なので、 非常に研究がやりやすい」と松本教授。
実際、研究室に所属する博士後期課程の学生は16人と多く、その中で、米国、中国、インドネシア、ブラジル、香港からの留学生 がいる。毎年、文系の学生が2割前後所属し、理系の情報系以外の学生も多い。「欧米だと、この分野は、言語学とコンピューター・サイ エンスの両方を勉強しているなどの経歴が多いが、日本ではそういう人が非常に少なく、そういう人材を育てられる」と期待する。
ケビン・デュー助教は、ワシントン大学などで学位を取得し、本学に赴任して3年目。日英の機械翻訳と、機械学習の手法である ディープ・ラーニング(深層学習)という技術を使って、自然言語処理の研究をしている。
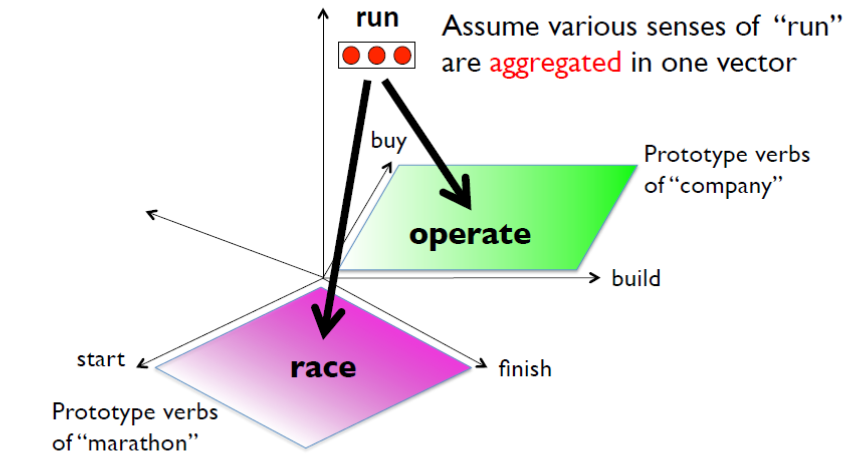
昨年、シアトルで開かれた国際会議で発表し、好評だったのは単語と文の意味をパソコンの中で表現する新手法。たとえば、人間が「イヌ」という単語を見て脳の細胞が反応したら、関連して別の細胞がその意味としてイヌの姿 をイメージする。そのような形の手法で、す べて数値計算で表した。「数式を定義して大規模データを使って学習したら、結構いい精度 の言語理解ができました」と語る。
もともと工学のほか、文学や人間社会学にも興味があり、大学院で自然言語処理の研究を初めて知って「言葉という人間性があるものも工学の視点から見られるのが面白い」と思ったのがきっかけで研究を始めた。研究に 対しては「毎日続ける」が信条で、そのために、「ジャスト・ドゥ・イット」(行動あるのみ) と自分に言い聞かせている。

ケビン・デュー助教は「本学の環境は自由で楽しい。教員や学生も優れている。米国で は教授が大きな予算を取り、それで学生を雇う形なので仕事としてのプレッシャーがある かわりにいい成果も出る」という。自分の研究、キャリアにとってよいかどうかによって就職先の優先順位を決めているが、「松本研究室は 世界的なプレゼンスがあり、米国の大学で教官から最初に渡された構文解析の論文の著者 は松本教授だった」という因縁がある。「将来 のことはまだ決めていない。本学では5年任 期なので、自分の研究ができるところならどこへでも行くのが研究者人生」と話す。博士後期課程1 年のフランセス・ユングさんは、中国・香港の出身で国費留学生。中国語と英語の間での「文」の機械翻訳を研究している。大学院修士課程まで文系で翻訳作業 の経験もあることから、「人間は文を訳すときに、まず全体を把握する。機械翻訳にはない やり方を提案して研究しています」という。松本教授については文献で知っていたが、「自然言語処理」でネット検索したら、真っ先に 出てきたので留学先を決めた。「小規模な大学なので、すぐに顔を覚えてもらえ、留学生同士の英語のコミュニティーができていて楽しい。英語の授業もある」と満足気。小学生2 人の母親でもあり、「子育てしながら研究できるのも本学のいいところ」。
日本の古文の解析というユニークなテーマ で研究しているのは、博士後期課程3 年の岡照晃さん。国立国語研究所で行っている平安時代から明治のころまでの日本語のコーパス (データベース)づくりを、手作業でなく自動化する研究に取り組んでいる。「現代人にも検索しやすくしたいのですが、原文は濁点が付いていなかったり、仮名遣いが整っていなかったり、表記がまちまちで、文字列を入力して も結果が得られない。そこで、もっとも重要 な濁点を付けるべき場所について、周囲の文 字情報だけで判断して濁点を付けるというアプリケーションをつくり自動化に成功しています」と成果を喜ぶ。「研究室のいいところは、言葉に対する興味を持つ人たちが集まっているので、研究の話がいつでもどこでもできることでしょう」と話している。


